
Log file analysis is something that I like the most regarding a website’s technical analysis. It makes me think and act according to the insights I get based on the log file data. Whenever I receive log files for a website, I try to understand why search engines crawl those URLs the most or less.
I’m here to share a study on the log file analysis I got in the last year. Previously, I shared all the considerable essential knowledge on the Screaming Frog blog, where I analyzed an e-commerce website with over 7 million log file events. Those log file events ended up being around 32 million.
In the meantime, I analyzed various websites’ server log files from multiple industries. Below I’ll include the learnings based on the data from 32 million log file events and other websites where I received the log files. Before starting, I’d like to clarify the context of the server log files.
Includes
What is server log file analysis?
Analyzing the server log files allows you to receive the data based on how search engines like Google crawl a website. By analyzing these log file events, you will understand where Googlebot, Yandexbot, Bingbot, or other major search engines are wasting or investing time in crawling your web pages.
In this case, the server log file analysis study is only based on search engine activities.
What kind of data is in server log file events?
You can see many things whenever you get enough log file events. But in a nutshell, you’ll be able to find:
- How are search engines crawling a website?
- Do search engines crawl pages that shouldn’t crawl?
- Do search engines crawl the robots.txt file?
- How often are the most critical pages crawled?
- Do search engines crawl any broken pages?
- Are there any pages with server timeout issues?
- Which external resources are pointing to the pages?
The above questions and more can be found in the official log file events.
How to ensure you got the correct log file for SEO?
There might be various official and non-official log events regarding requesting for SEO purposes. For example, if you only want to receive the log file events that belong to Google, you will need to ensure that the log file lines include an IP address starting with 66.249. There are multiple user agents of Googlebot, so you must ensure that the IP addresses are official.
Non-official log file events can be due to tools that analyze the website. DeepCrawl, ContentKing, Ahrefs, and Semrush crawlers have their IP addresses, for example. From these tools, anyone can crawl a website and will be included in the log files when someone crawls a website.
Example official log file of a Googlebot event:
66.249.76.201 – [22/Aug/2022:22:31:50 +0100] “GET /landing-page HTTP/1.1” 200 889484 “-” “Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.119 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)” 127 cookie:-
The above example log is only a line from the log file events from an official Googlebot user agent request.
What Data Would You Need to Analyse the Log Files?
- Requested URL: this will show the URL crawled by a user agent.
- Timestamp: this will show when (exact date and time) a user agent requests to crawl a URL. In the above example log line is [22/Aug/2022:22:31:50 +0100].
- Remote Host: this will show which IP address is requested to crawl a URL. If you’re looking for Googlebot log file events, you’ll need to find only the IP addresses that start with 66.249. In the above example is 66.249.76.201.
- User Agent: this will show what type of user agent is requested to crawl a URL. If we take the IP addresses that start with 66.249, in this case, they can be “Googlebot”, “Googlebot Smartphone”, “Googlebot Image”, and more that is related to Googlebot user agents. In the above example is “Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.119 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”.
- Method: this will show if the URL was requested from a specific resource as a “GET” request method or if the URL was processed to a particular resource as a “POST” method. In many cases, the method request will be GET, which is the most common HTML request method. In the above example is indicated as “GET”.
- HTTP Version: this will show the HTTP version. I’ve seen the HTTP version in many cases as either 1.1 or 2.0. In the above example is HTTP/1.1.
- Response Code: this will show the URL’s returning status code, such as “200-OK”, “301 Permanent Redirect”, “404 Not Found”, “500 Server Error”, and so on.
- Referer: this will show which page referred to crawl any of the linked URLs. This can be an external or internal source.
As I’ve clarified, I’ll share my latest log file analysis learning below.
Log File Analysis is Not About Getting Ranked 1st Tomorrow
Just because you found some insights on log files and took actions accordingly, this won’t help you to get ranked tomorrow.
Log files are about understanding complex technical things that can’t be easily seen without analyzing them. Log file events will allow you to see where search engines are wasting or investing time while crawling a website.
Technical SEO solutions, most of the time, are about long-term solutions and results, which can impact the whole organic performance.
More Log File Events, More Actionable Insights
Log file events don’t mean anything if you don’t get meaning from the data you receive. Analyzing the log events for only one month might mean just thousands of log file hits.
You must be on track for at least a few months to get more meaningful insights and act accordingly. In my experience, I saw many scenarios where Google crawled pages for a month, but those pages weren’t indexed yet.
Whenever a page is crawled, it doesn’t mean it will be indexed immediately, especially when it’s high with JavaScript. This blog post from Ziemek of Onely covers it in more detail: “It takes 9x more time for Google to crawl JavaScript than HTML.”
Tracking the log file hits for extended periods will allow you to learn more and understand whenever those results need action.
Try to Understand If the Log File Results Need Actions
You can have thousands of broken pages in the log file events, but:
- If none of those pages is in an HTML format,
- None of those pages was indexable on search engines,
- None of those pages got traffic from any channels.
It’s nonsense to redirect them somewhere else. Prioritizing these broken links to redirect won’t improve the website’s crawl budget. In most cases, improving the crawl budget is about optimizing millions of URLs crawled by Googlebot but not indexed.
Google Never Forgets a URL That Ever Existed
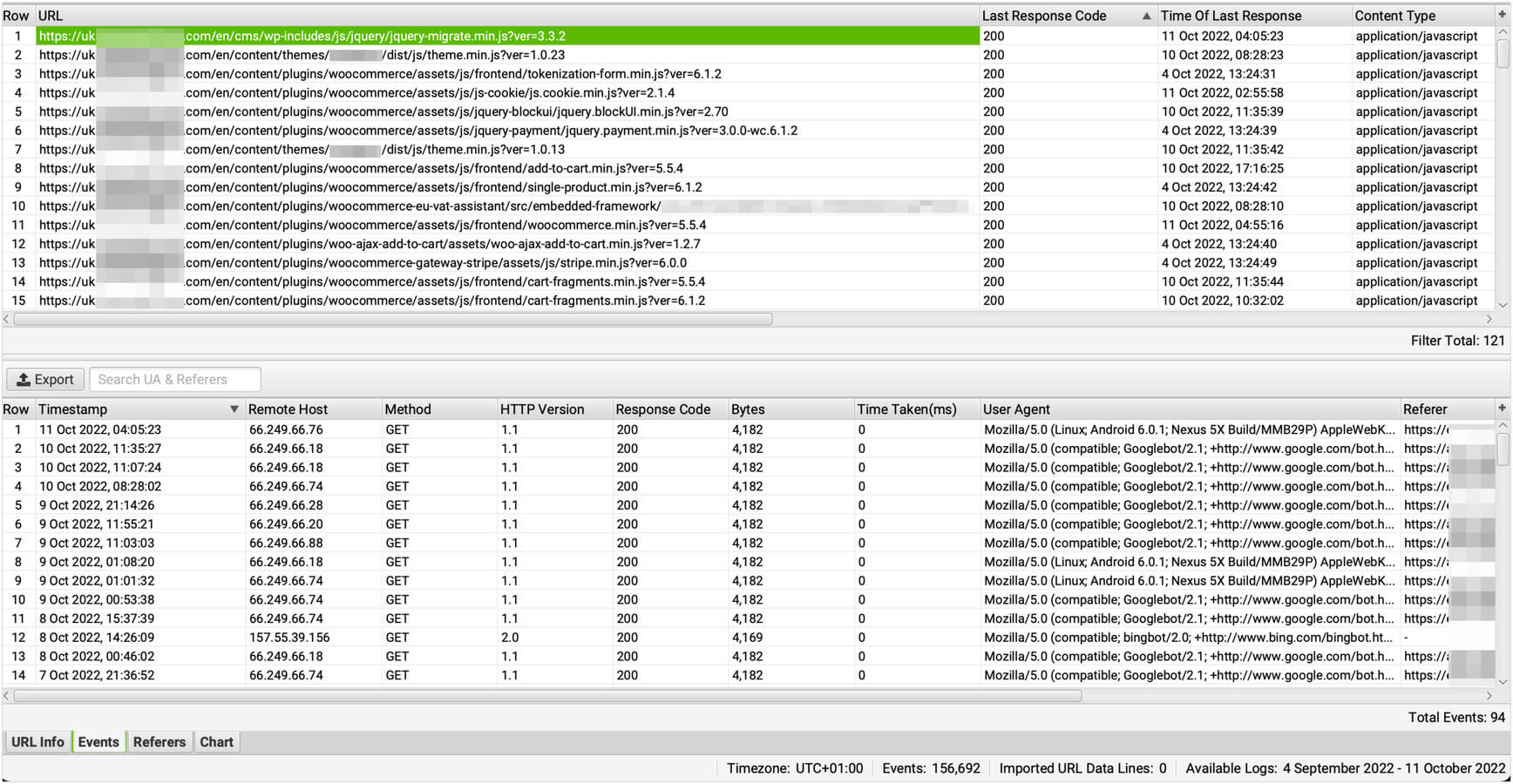
Google never forgets a URL that ever existed. Even a script URL, as you see in the above image.
I’d strongly advise you to only pay attention to those issues that can positively impact your organic performance.
E.g.,
Broken but valuable pages should be 301-redirected for at least one year. Redirecting these pages to a relevant page is the best practice.
When you get broken pages that once were valuable for your business, try to 301-redirect all of them to another related page. Keep the 301 redirections for at least one year since Googlebot constantly crawls them. It’s also recommended by Google (Google’s John Mueller and ex-Googler Matt Cutts).
Treat Valuable Broken Pages Like Dead Backlinks from Useful Resources
Treat valuable broken pages like dead backlinks from useful resources.
You will lose the backlink’s value from that external resource if you don’t redirect the broken linked page elsewhere. It’s the same for your internal broken pages with or without backlinks.
To find broken internal links, you can use Screaming Frog’s SEO Spider broken link checker, as it’s the easiest way I’ve experienced.
You Don’t Need to Remove All the “404 Not Found” Pages Intentionally
You don’t need to intentionally remove all 404 pages (by making them return a “410 Gone” status code). I was wrong when I said Googlebot wouldn’t crawl 410 intentionally removed pages more than two times. I kept analyzing the log file events for the “410 Gone” URLs, and from what I’ve experienced, Googlebot kept crawling those URLs. The only difference I’ve seen is that “410 Gone” URLs can slightly be less crawled compared to the “404 Not Found” URLs.
Having 404 pages is also not a bad practice from a crawl budget perspective. You only lose the value of that page if you don’t redirect it.
A Better View of Log File Events

If you want a better view of log file events, export clicks from Google Search Console and page speed score from PageSpeed Insights data. To easily export this data, you can use Screaming Frog SEO Spider’s GSC and PSI integration APIs.
When you get this data, import it into Screaming Frog Log File Analyser. This will allow you to make better decisions while prioritizing the technical fixes. You can see my research and learnings in the blog post I shared with Screaming Frog.
Using WooCommerce for WordPress
If you’re using WordPress and have WooCommerce but don’t show products on every page, ensure that you disable the “AJAX add to cart buttons” option, as this will make a filter parameter and will be crawled by Googlebot every single time.
Googlebot Will Always Crawl the Ads.txt File
Ads.txt file will be crawled by Googlebot all the time. This is not a problem, even if the /ads.txt URL returns a 404 status code. It’s a part of your crawl budget; Googlebot will crawl the ads.txt file consistently to ensure that your website includes AdSense.
Adx.txt file is for the website owners to protect the earnings from Google AdSense.
An Alternative to Server Log File Analysis: Crawl Stats
If you can’t export the log files, use Crawl Stats on your Google Search Console account. This is also an alternative to log file analysis, but with a 1K row and 90-day limit.
Crawl stats have many great features you won’t see on the log files. One of the features I like the most is under the “By purpose” report, which shows if the URLs in the list were crawled for the first time (under “Discovery”) or it was crawled for refresh purposes (under “Refresh”).
Crawl stats can be found under settings in your Search Console property.
What % of Log File Analyses Result in Actionable Insights?
I’ve got this question from Andrew Shotland on Twitter, and I believe many of you could ask the same, as it was interesting for me, too.
I’ll continue studying the log file events, investigating how search engines crawl websites, experimenting with things considered “best practices” that have yet to be tested, and having fun.
In the meantime, if you want to support and keep me motivated, you can share this post on Twitter or your LinkedIn account.